
728x90

0.개요
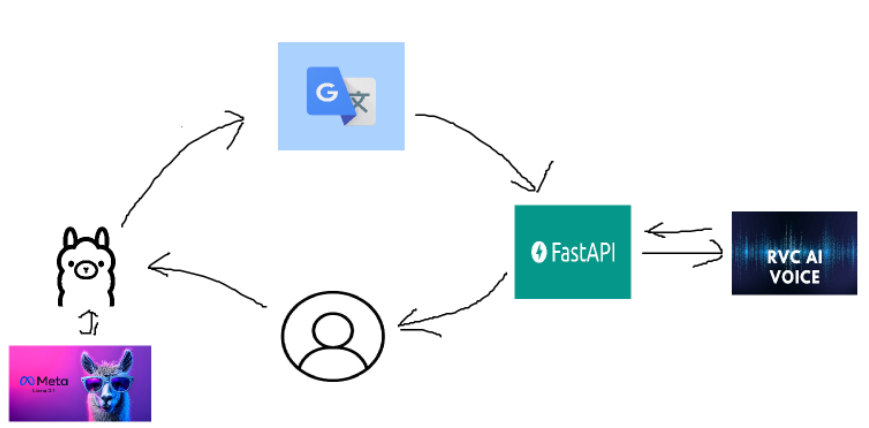
기존 gradio API를 사용하던 Applio를 업데이트 하니 API 사용이 사라졌다....
이게 무슨일인가싶어서 Github 이슈에 들어가서 확인해보았다.
아이고... 확인해보니 더이상 제공하지않고 답변을 확인해보니 core.py에 있는 요소들을 사용해서 직접 서버를 구축해야될거같다.
1.FASTAPI 구축하기
Core.py를 살펴본 결과 다음 메소드가 내가 원하는 텍스트를 wav 파일로 TTS 해주는 메소드임을 확인하였다.

그래서 main.py를 따로 생성하여 FASTAPI 서버를 구축하여 /tts 경로로 엔드포인트를 생성해줬다.
from fastapi import FastAPI, Form
from typing import Optional
import os
from core import run_tts_script # core.py에서 필요한 함수 임포트
app = FastAPI()
@app.post("/tts")
async def tts(
tts_file: str = Form(...),
tts_text: str = Form(...),
tts_voice: str = Form(...),
tts_rate: int = Form(...),
pitch: int = Form(...),
filter_radius: int = Form(...),
index_rate: float = Form(...),
volume_envelope: int = Form(...),
protect: float = Form(...),
hop_length: int = Form(...),
f0_method: str = Form(...),
output_tts_path: str = Form(...),
output_rvc_path: str = Form(...),
pth_path: str = Form(...),
index_path: str = Form(...),
split_audio: bool = Form(False),
f0_autotune: bool = Form(False),
f0_autotune_strength: float = Form(1.0),
clean_audio: bool = Form(False),
clean_strength: float = Form(0.7),
export_format: str = Form("WAV"),
f0_file: Optional[str] = Form(None),
embedder_model: str = Form("contentvec"),
embedder_model_custom: Optional[str] = Form(None),
sid: int = Form(0),
):
try:
message, output_file = run_tts_script(
tts_file=tts_file,
tts_text=tts_text,
tts_voice=tts_voice,
tts_rate=tts_rate,
pitch=pitch,
filter_radius=filter_radius,
index_rate=index_rate,
volume_envelope=volume_envelope,
protect=protect,
hop_length=hop_length,
f0_method=f0_method,
output_tts_path=output_tts_path,
output_rvc_path=output_rvc_path,
pth_path=pth_path,
index_path=index_path,
split_audio=split_audio,
f0_autotune=f0_autotune,
f0_autotune_strength=f0_autotune_strength,
clean_audio=clean_audio,
clean_strength=clean_strength,
export_format=export_format,
f0_file=f0_file,
embedder_model=embedder_model,
embedder_model_custom=embedder_model_custom,
sid=sid,
)
return {"message": message, "output_file": output_file}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(
"main:app", # "파일이름:FastAPI 객체 이름"
host="127.0.0.1", # 또는 "0.0.0.0" (외부에서 접근 가능)
port=8000, # 원하는 포트 번호
reload=True # 개발 모드에서 코드 변경 시 자동 재시작
)
생성한 FASTAPI 서버를 실행후 ChatBot의 TTS에 있던 파일또한 바뀐 EndPoint에 맞게 수정해줬다.
import pyaudio
import wave
import time
import threading
import numpy as np
import requests
class TTS:
def __init__(self):
self.url='http://127.0.0.1:8000/tts'
self.file_path="C:/Users/asa/Desktop/Applio-main/assets/audios/"
self.wav_path=self.file_path+ "tts_rvc_output.wav"
def convert_tts(self, text):
data = {
"tts_file": self.file_path + "tts_output.wav", # 입력 파일 경로
"tts_text": text,
"tts_voice": "ja-JP-NanamiNeural",
"tts_rate": 0,
"pitch": 6,
"filter_radius": 3,
"index_rate": 0.75,
"volume_envelope": 1,
"protect": 0.5,
"hop_length": 128,
"f0_method": "rmvpe",
"output_tts_path": self.file_path + "tts_output.wav",
"output_rvc_path": self.wav_path,
"pth_path": "logs/meguminV2d_e420/meguminV2d_e420.pth",
"index_path": "logs/meguminV2d_e420/added_IVF3146_Flat_nprobe_1_meguminV2d_e420_v2.index",
"split_audio": False,
"f0_autotune": False,
"f0_autotune_strength": 1.0,
"clean_audio": True,
"clean_strength": 0.5,
"export_format": "WAV",
"embedder_model": "contentvec",
"embedder_model_custom": None,
"sid": 0,
}
try:
response = requests.post(self.url, data=data)
response.raise_for_status() # 요청이 실패하면 예외 발생
result = response.json()
print("TTS 변환 완료:", result["message"])
except requests.exceptions.RequestException as e:
print("TTS 변환 중 오류 발생:", e)
def play_wav(self, volume=0.3):
chunk = 1024
with wave.open(self.wav_path, 'rb') as f:
p = pyaudio.PyAudio()
stream = p.open(
format=p.get_format_from_width(f.getsampwidth()),
channels=f.getnchannels(),
rate=f.getframerate(),
output=True
)
data = f.readframes(chunk)
while data:
# 데이터 볼륨 조절
audio_data = np.frombuffer(data, dtype=np.int16) # 16비트 오디오 데이터로 변환
audio_data = (audio_data * volume).astype(np.int16) # 볼륨 조절
data = audio_data.tobytes() # 바이트로 다시 변환
stream.write(data)
data = f.readframes(chunk)
stream.stop_stream()
stream.close()
p.terminate()
def timer(self):
start_time = time.time()
while not self.stop_timer:
elapsed_time = time.time() - start_time
print(f"\r경과 시간: {elapsed_time:.2f}초", end="")
time.sleep(0.01)
def play_TTS(self,text="ボイスボックスに問題が発生しました"):
self.stop_timer= False
timer_thread = threading.Thread(target=self.timer)
timer_thread.start()
self.convert_tts(text)
self.play_wav()
self.stop_timer = True
timer_thread.join()
728x90
'Language > Python' 카테고리의 다른 글
| [Python] RVC + LangChain 으로 TTS 챗봇만들기2 (0) | 2025.01.13 |
|---|---|
| [Python] langchain + VoiceVox 로 tts 챗봇 만들기 (0) | 2025.01.12 |
| [Python] 애니 데이터 크롤링 (0) | 2024.07.28 |