
728x90

구버전 글입니다.
0.개요
지난번 유튜브에서 본 VoiceVox로 TTS챗봇을 만들기를 해봤는데
여기서 TTS부분을 RVC 모델을 사용한것으로 바꾸기 하였다.
https://asa9874.tistory.com/576
[Python] langchain + VoceVox 로 tts 챗봇 만들기
0.개요유튜브를 돌아다니다가 한 영상을 접하게 되었다.How to Make Your Own AI Waifu Virtual VTUBER or Assistant (당신만의 AI 버튜버나 Assistant를 만드세요) 최근 LangChain을 배우고 있는 도중이라 보던
asa9874.tistory.com
1.RVC(Retrieval-based Voice Conversion)
음성 변환 기술의 한 종류이다.
음성 데이터를 다른 음성데이터로 바꾸는 기술이지만 TTS로도 이용할수있으니 RVC 모델을 사용하도록 하자
모델들은 HuggingFace에서 찾거나 Discord의 AI Hub 채널에서 쉽게 구할수있다.
2.Applio
Applio는 개인화된 음성을 만들거나 다양한 기존 음성을 활용할 수 있는 강력한 AI 기반 음성 변환 도구이다.
이번 프로젝트는 해당 프로그램을 로컬환경에서 실행한 상태로 진행하였다.
https://docs.applio.org/applio/getting-started/installation
Applio - Installation
Applio is easy to install. We recommend the precompiled version for new users as it's ready to use.
docs.applio.org
Appilo를 실행하면 다음과같은 창이 나오게 되는데 우리가 필요한것은 TTS이므로 TTS 란으로 이동한다.
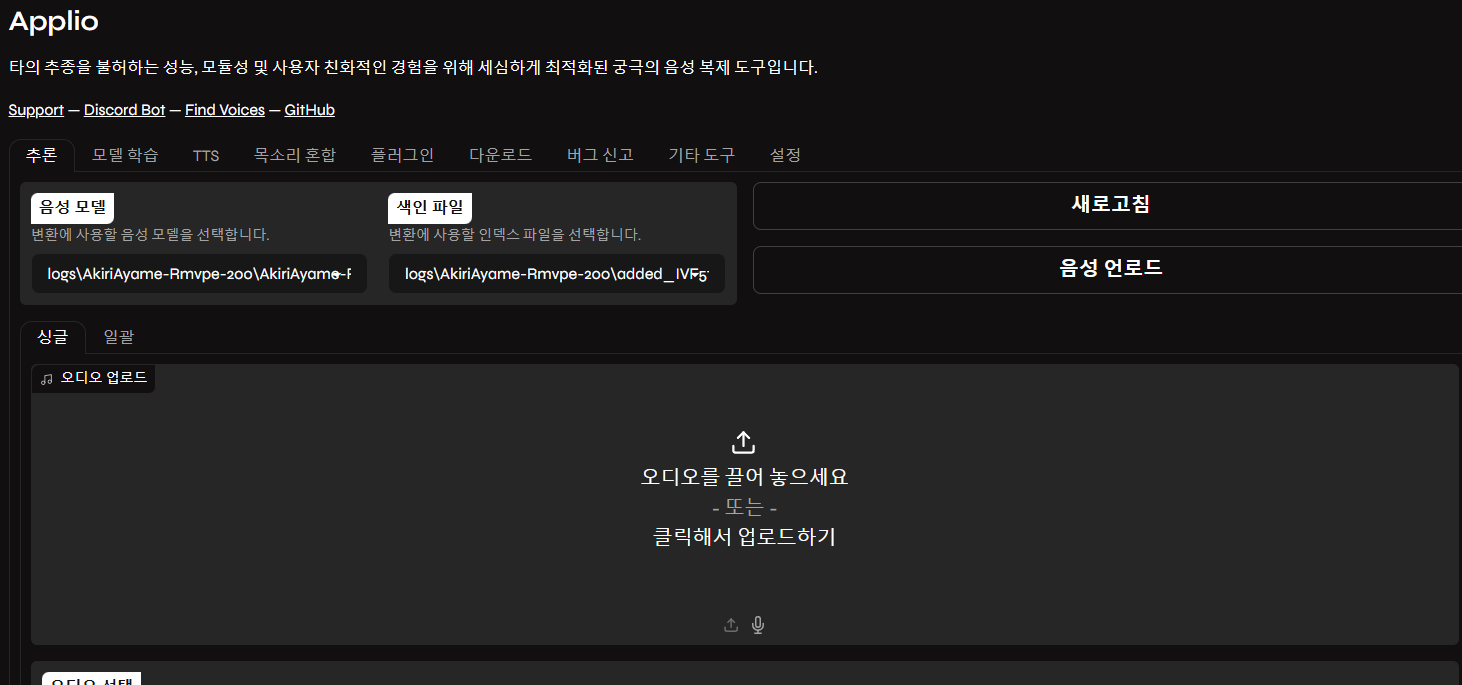
그후 음성모델에서 자신이 다운로드한 RVC 모델을 선택해준다.

그후 음성 언어를 세팅 해주는데 나는 JP 를 선택해줬다.

합형할 텍스트에는 TTS로 말할 문장을 적는다.

그후 하단 고급 설정을 눌러서 다음과같이 맞춰줬다.
Embedder Model을 japanese-hubert-base로 바꾸고 Pitch를 6으로 세팅해줬다.
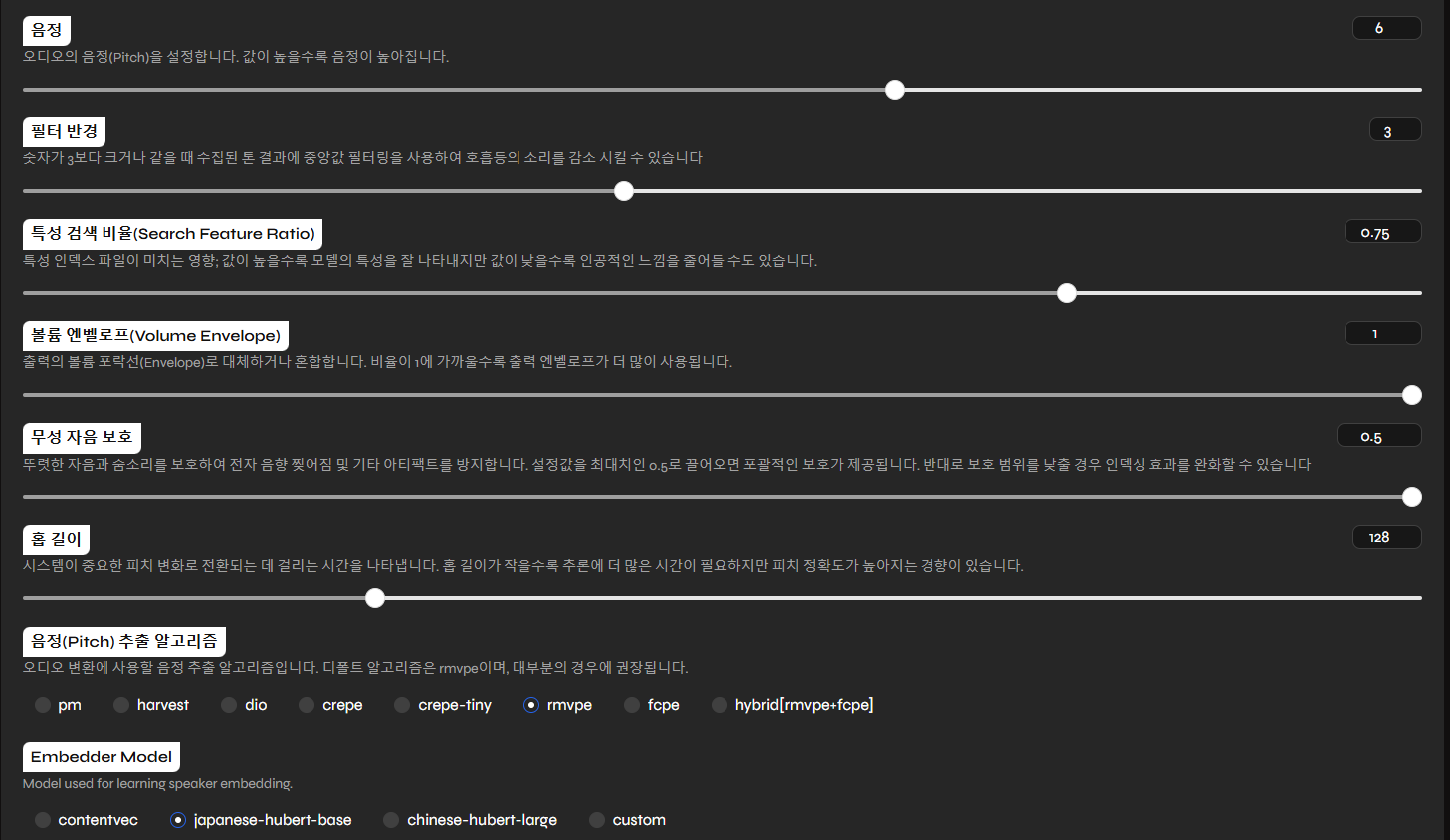
이제 하단의 변환을 누르면 선택한 RVC 모델로 TTS를 들을수있다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
이거를 API로 내 프로젝트에서 사용하는방법은 간단하다
우선 화면을 쭉내려서 해당 버튼을 찾아서 누른다.
그후 상단에 있는 API Recorder을 누른뒤 다시
TTS 변환 버튼을 눌러서 오디오 파일을 만들어낸다.
그러면 좌측 하단에 다음과같이 뜨게 되는데 누르게 되면

다음과같이 코드를 Python에서 쓸수있는 코드를 주게 된다. 이제 이것을 이용해서 기존 VoiceVox 코드를 수정해보자.

기존 TTS 클래스를 다음과 같이 수정하였다.
from gradio_client import Client
import os
import pyaudio
import wave
import os
import time
import threading
import numpy as np
class TTS:
global url
global stop_timer# 타이머 종료용
global file_path # 폴더경로
global wav_path # wav 파일 경로
global client
def __init__(self):
self.url='http://127.0.0.1:6969/'
self.file_path="C:/!MY_FOLDER/Applio-3.2.1/assets/audios/"
self.client = Client("http://127.0.0.1:6969/")
self.wav_path=self.file_path+ "tts_rvc_output.wav"
def convert_tts(self,text):
self.client.predict(
tts_text=text,
tts_voice="ja-JP-NanamiNeural",
tts_rate=0,
f0_up_key=6,
filter_radius=3,
index_rate=0.75,
rms_mix_rate=1,
protect=0.5,
hop_length=128,
f0_method="rmvpe",
output_tts_path=self.file_path+ "tts_output.wav",
output_rvc_path=self.wav_path,
pth_path="logs\meguminV2d_e420\meguminV2d_e420.pth",
index_path="logs\meguminV2d_e420\added_IVF3146_Flat_nprobe_1_meguminV2d_e420_v2.index",
split_audio=False,
f0_autotune=False,
clean_audio=True,
clean_strength=0.5,
export_format="WAV",
embedder_model="japanese-hubert-base",
embedder_model_custom=None,
upscale_audio=False,
f0_file=None,
api_name="/run_tts_script"
)
def play_wav(self, volume=0.6):
chunk = 1024
with wave.open(self.wav_path, 'rb') as f:
p = pyaudio.PyAudio()
stream = p.open(
format=p.get_format_from_width(f.getsampwidth()),
channels=f.getnchannels(),
rate=f.getframerate(),
output=True
)
data = f.readframes(chunk)
while data:
# 데이터 볼륨 조절
audio_data = np.frombuffer(data, dtype=np.int16) # 16비트 오디오 데이터로 변환
audio_data = (audio_data * volume).astype(np.int16) # 볼륨 조절
data = audio_data.tobytes() # 바이트로 다시 변환
stream.write(data)
data = f.readframes(chunk)
stream.stop_stream()
stream.close()
p.terminate()
def timer(self):
start_time = time.time()
while not self.stop_timer:
elapsed_time = time.time() - start_time
print(f"\r경과 시간: {elapsed_time:.2f}초", end="")
time.sleep(0.01)
def play_TTS(self,text="ボイスボックスに問題が発生しました"):
self.stop_timer= False
timer_thread = threading.Thread(target=self.timer)
timer_thread.start()
self.convert_tts(text)
self.play_wav()
os.remove(self.wav_path)
self.stop_timer = True
timer_thread.join()
3.결과
Applio 서버를 실행하고 프로그램을 실행해야하지만 내가 원하는 RVC 모델로 TTS 챗봇을 실행하는것에 성공하였다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
728x90
'Language > Python' 카테고리의 다른 글
| [Python] RVC+ FASTAPI + LangChain 으로 TTS 챗봇만들기3 (0) | 2025.01.13 |
|---|---|
| [Python] langchain + VoiceVox 로 tts 챗봇 만들기 (0) | 2025.01.12 |
| [Python] 애니 데이터 크롤링 (0) | 2024.07.28 |