
728x90

1.정책 (Policy)
에이전트가 각 상태에서 어떤 행동을 선택할지에 대한 전략이나 규칙을 나타내는 함수
강화학습에서 정책은 에이전트의 행동을 결정한다.
π(a|s)로 표현되며, 이는 상태 s에서 행동 a를 선택할 확률이다.
2.정책의 종류
2-1.확률적 정책 (Stochastic Policy)
주어진 상태에서 여러 행동 중 하나를 선택할 확률을 기반으로 행동을 결정한다.
주어진 상태에 대해 각 행동이 선택될 확률이 정의된다.
2-2.결정적 정책 (Deterministic Policy)
결정적 정책은 주어진 상태에서 항상 동일한 행동을 선택을 한다.
정책은 항상 특정한 행동을 선택하게됨
환경이 매우 복잡하거나 동적인 경우, 다양한 행동을 시도할 수 없다는 점에서 유연성이 부족할수있음
2-3.정책 경사법 (Policy Gradient)
확률적 정책을 직접 학습하는 방법으로, 정책의 파라미터를 업데이트하여 보상을 최대화하는 방식이다.
3.가치 (Value)
주어진 상태나 상태-행동 쌍이 얼마나 "좋은지"를 나타내는 척도
(에이전트가 특정 상태에서 시작하여 장기적으로 얻을 수 있는 보상의 기대값)
3-1.상태 가치 함수 (State Value Function, V)
특정 상태 s에서 시작하여, 그 상태에 따른 정책을 따랐을 때 에이전트가 얻을 수 있는 총 보상의 기대값
(상태 s에 있는 에이전트가 선택한 행동에 따라 장기적으로 기대할 수 있는 보상의 합을 평가)
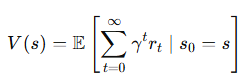
3-2.행동-가치 함수 (Action-Value Function, Q)
특정 상태 s에서 특정 행동 a를 취했을 때, 그 행동을 따랐을 때 얻을 수 있는 장기적인 보상의 기대값
(이는 특정 상태에서 어떤 행동을 취했을 때, 이후 발생할 보상들의 기대값을 평가)
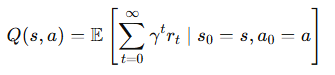
728x90
'AI' 카테고리의 다른 글
| [강화학습] openai gym 기본 구조 (1) | 2025.01.24 |
|---|---|
| [강화학습] 강화학습(Reinforcement Learning, RL) (0) | 2025.01.24 |
| [OpenCV] 영상 캡쳐,녹화 (0) | 2025.01.18 |